人工智能技术赋能与知识产权法适配 基于CSDN文库资源的交叉研究

人工智能技术的迅猛发展,正以前所未有的方式重塑技术研发、内容创作与产业应用格局。从机器学习、自然语言处理到计算机视觉,其技术实现离不开海量数据、算法模型与算力支撑。与此这些技术本身及其产出成果,也向以保护人类智力劳动成果为核心的传统知识产权法律体系提出了深刻的适配性挑战。本文旨在从知识产权法的视角,探讨人工智能技术涉及的若干核心问题,并借助CSDN文库等平台中的人工智能基础资源与技术研究论文,分析现有法律框架的应对与可能的演进方向。
一、 人工智能技术成果的知识产权客体界定难题
人工智能技术本身具有高度的复杂性与抽象性。其核心要素主要包括:
- 算法与模型:作为AI的“灵魂”,其创新性体现在数学逻辑与架构设计上。目前,专利法通常保护“技术方案”,纯粹的数学方法或抽象算法往往被排除在外。当算法与具体的硬件或应用场景紧密结合,形成解决特定技术问题的方法时,便可能获得发明专利的保护。CSDN文库中大量关于模型优化、架构创新的技术论文,其核心思想在寻求专利保护时,需精准界定其“技术贡献”部分。
- 训练数据:数据是AI的“燃料”。数据集的构建、清洗与标注本身可能构成具有独创性的汇编作品,受著作权法保护。但数据本身(尤其是原始事实数据)通常不被视为作品。使用受版权保护的数据进行训练,可能涉及“合理使用”的边界争议,这在生成式AI的背景下尤为突出。
- 生成内容:由AI自主或辅助生成的文章、代码、图像、音乐等,其著作权归属是当前争论的焦点。传统著作权法要求作品必须源于“人类作者”的智力创作。因此,完全由AI自主生成、无人为实质性贡献的内容,在许多法域难以被认定为作品并获得著作权。CSDN上分享的由AI辅助生成的代码片段,其版权声明与使用许可便需格外谨慎。
二、 知识产权法主要领域的适配性分析
- 专利权:保护AI技术方案的核心壁垒。挑战在于如何清晰撰写权利要求,以覆盖算法在应用中的功能性实现,同时避免落入抽象概念。审查中对“创造性”的判断标准也需适应AI领域技术迭代快、组合创新的特点。研究论文中公开的技术细节,可能影响后续专利申请的“新颖性”。
- 著作权:主要保护AI软件代码(作为计算机程序)以及AI生成内容中的人类贡献部分。对于AI工具(如集成开发环境、模型框架)的使用,需遵守其对应的开源协议(如GPL、Apache License)或商业许可。CSDN文库中的技术文章、代码示例本身是受版权保护的作品,引用或二次开发需尊重原作者的署名权等权利。
- 商业秘密:对于未公开的专有算法、核心参数(如模型权重)、独特数据集,企业常采用商业秘密进行保护。其优势在于无期限限制,但一旦泄密则保护丧失。技术社区中的交流与开源运动,与商业秘密保护存在一定的张力。
- 数据与算法治理:这已超出传统知识产权范畴,进入更广泛的数据产权、个人信息保护及算法透明度监管领域(如欧盟《人工智能法案》)。合规使用数据资源进行AI研发成为前提。
三、 基于CSDN文库资源的实践观察与研究启示
CSDN作为中文IT技术社区与资源平台,其文库汇聚了大量人工智能领域的基础教程、技术解析、研究论文与实践项目代码。这为观察AI技术与知识产权互动的实践提供了丰富样本:
- 知识共享与产权保护的平衡:平台上的资源大量采用开源许可证发布,促进了技术扩散与合作创新。研究者在借鉴或使用这些资源时,必须明确其许可条款,规范引用与再发布行为。
- 技术论文的“公开”与专利“新颖性”:许多技术突破首先以论文形式在社区传播(包括预印本)。这提示研发主体需做好知识产权布局规划,在公开研究成果前评估专利申请的必要性与时机,避免因先行公开而丧失专利授权机会。
- 社区贡献的产权归属:社区协作开发的AI项目(如某些开源模型),其贡献者权利归属通常由贡献者协议(如CLA)约定,明确版权许可与专利授权范围,这对项目的长期发展至关重要。
结论与展望
人工智能技术的知识产权保护,是一个动态演进的法律与技术交叉领域。当前法律体系正在通过司法判例、行政审查指南修订乃至立法活动进行调适。未来的方向可能包括:探索对AI生成物设定新的邻接权保护;细化算法专利的审查标准;建立数据要素产权制度的“三权分置”运行机制;以及通过标准化开源协议来促进创新协作。对于AI技术开发者与研究者而言,增强知识产权意识,在利用CSDN等平台资源进行学习与研究的主动管理自身创新成果的知识产权,并尊重他人的智力劳动,是在AI时代进行负责任创新的必备素养。法律与技术社区需持续对话,共同构建既能激励AI前沿创新,又能保障公平秩序与伦理底线的规则环境。
最新产品

人工智能基础资源与技术 CSDN开发者文库的IT技术下载指南
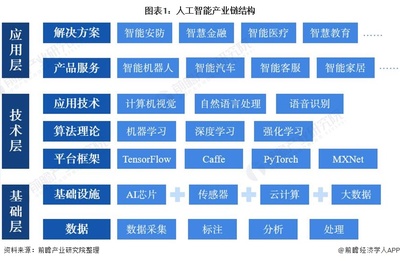
2022年中国人工智能芯片行业 基础资源、技术现状与发展趋势分析
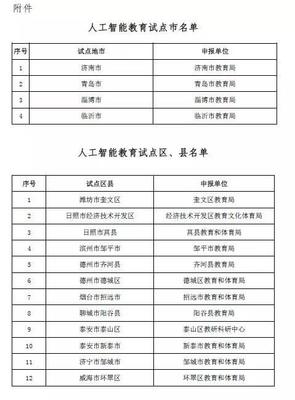
山东启动人工智能教育新篇章 721所学校成为首批试点

谋篇布局 河北人工智能计算中心如何激活AI发展的新动能

最适合人工智能开发的5种编程语言与核心入门资源指南

科技部再发支持函,四城获批建设国家级AI试验区——京雄AI前沿一周要闻聚焦

浅谈电气自动化控制中的人工智能技术
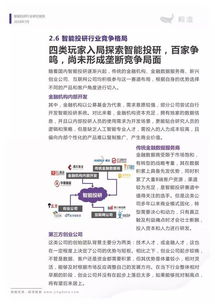
智能投研行业分析报告 人工智能基础资源与技术的现状、挑战与未来

偶数科技数据库OushuDB 赋能湖北公安大数据智能化建设与人工智能技术融合

解锁人工智能学习资源 CSDN开发者文库与会员免费下载指南